What are we gonna do in this blog?
Learning about what goes behind random forest. What is it that beginner struggles understanding random forest. What makes random forest so powerful. Further, we will discuss intuition behind random forest. Explaining random forest in detail with own handcrafted code and sklearn provided.
Personal Experience
When i was starting out with Machine Learning. All i could see the hype of Random Forest being powerful and quite handy in use. I was abit curious. So, i started learning about it in depth. It became a bit hard to comprehend the words like ensemble and random forest in general. But after understanding it, i can say it’s really makes sense why random forest works. I’ll be sharing what are my key insights on this.
What is the intuition behind Random Forest?
Random Forest is derived from the concept of Decision Tree. Assuming you know what decision trees are. In a nutshell, When we use lots of decision trees (i.e. 20,100,150) to train & predict the input data. This lot (or Group) of decision trees are known as ensemble. Rather than using single decision tree to finalize decision. We use many of them. It’s same as imagine you have to decide which book to buy for statistics. When you do is talking to many people and then buy which most of the people prefer.
Another example: Let’s say you going to interview. So there will be different rounds of interview and you will be evaluated on different features of yours. Finally, getting selected or not would be what most of the interviewer perceive. If 2 out of 3 agree with selection you will be selected. If 2 out of 3 don’t agree with selection, then you will be rejected.
Same Goes in Random Forest: You take many decision trees (it could be thousands too), for now let’s say 100 and each of them trained on random data points(row) of training data. Then you use, testing data and each decision tree will predict according to the feature they have been trained on.
Important: All the decision trees shouldn’t be trained on same features. That could lead to biased predictions.
Training on random features(reason why random forest are called random) allows to create more flexible and ungreedy algorithm. Decision tree uses greedy algorithm. So, it’s important to feed random features.

I hope, you get a bit clarity what it means when we say random forest. Although, your concepts will be totally cleared when you dive into coding the decision tree from scratch.
Coding our own Random forest
1
2
3
4
5
> from sklearn.datasets import make_moons
> from sklearn.model_selection import train_test_split
> mo= make_moons(n_samples=10000, noise=0.4) #creating toy data
> X_train, X_test, y_train, y_test= train_test_split(mo[0], mo[1], test_size=0.2, random_state=42)
Small peak into data and label.We are looking at first 5 data points and their label(or target). As you can see below, Left side array is X and Y value. And Right Side Array is labels of respective row value.
1
2
3
4
5
6
7
> X_train[:5], y_train[:5]
(array([[ 0.10186633, -0.20643133],
[-0.24668162, 1.0486827 ],
[-0.57215016, 0.30076258],
[ 0.05560597, 0.9361636 ],
[-0.91425428, -0.33931685]]), array([1, 0, 0, 1, 0]))
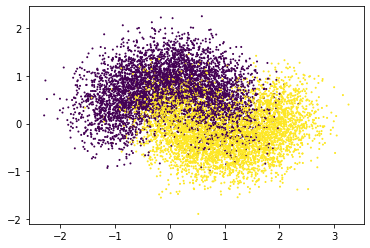
Just a simple look at our data. Green and Purple are the different classes and in this we have to predict if X and Y coordinates are provided what will be the class of the point.
1
2
3
4
5
%matplotlib inline
import matplotlib.pyplot as plt
plt.scatter(mo[0][:,0], mo[0][:,1], c=mo[1], s=1)
plt.show()