
Abstract allows us to understand paper:
We present a class of efficient models called MobileNets for mobile and embedded vision applications. MobileNets are based on a streamlined architecture that uses depth- wise separable convolutions to build light weight deep neural networks. We introduce two simple global hyper- parameters that efficiently trade off between latency and accuracy. These hyper-parameters allow the model builder to choose the right sized model for their application based on the constraints of the problem.
We present extensive experiments on resource and accuracy tradeoffs and show strong performance compared to other popular models on ImageNet classification. We then demonstrate the effective- ness of MobileNets across a wide range of applications and use cases including object detection, finegrain classification, face attributes and large scale geo-localization.
In a nutshell:
The mobilenet paper is inspired from Xception paper (my implementation). While in xception network. Author used depthwise convolutions followed by pointwise convolutions. This helped decreasing computational cost of the entire model quite much. Entire aim of mobilenet paper was to deliver state of the art model whose size is significantly less than previous SOTA(state-of-the-art) models like: VGG19, ResNet(34,50 etc), Inception etc.
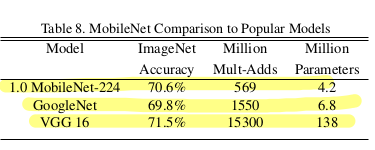
As you can see above, MobileNet model got 4.2 million parameters. Comparison to GoogleNet (6.8 million), VGG16 (128 million). That’s what is helpful. And suggested by this paper. MobileNet is nearly as accurate as VGG16 while being 32 times smaller and 27 times less compute intensive. It is more accurate than GoogleNet while being smaller and more than 2.5 times less computation.
Note: MobileNet comparison is not only limited to GoogleNet or VGG but also applicable to PlaNet, CoCo object detection etc.
MobileNet Main Discussion:
For MobileNets the depthwise convolution applies a single filter to each input channel. The pointwise convolution then applies a 1 × 1 convolution to combine the outputs the depthwise convolution.
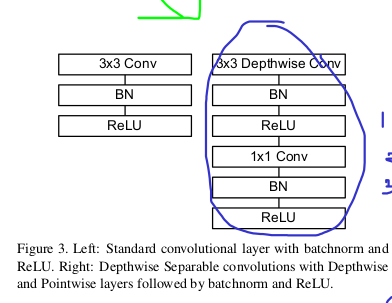
As you can see above. Instead of Standard Convolution strategy, we are using 3x3 depthwise convolution followed by Batch Normalization and ReLU. Later 1x1 pointwise convolution to complete our depthwise separable convolution layer.
- Depthwise separable convolution layer :
- 3x3 depthwise convolution
- 1x1 pointwise convolution
This factorization has the effect of drastically reducing computation and model size. Depthwise separable convolution are made up of two layers: depthwise convolutions and pointwise convolutions. We use depthwise convolutions to apply a single filter per each input channel (input depth). Pointwise convolution, a simple 1×1 convolution, is then used to create a linear combination of the output of the depthwise layer. MobileNets use both batchnorm and ReLU nonlinearities for both layers.
Architecture:
- Conv dw -> Depthwise convolution
- s -> stride
Counting depthwise and pointwise convolutions as separate layers, MobileNet has 28 layers. All layers are followed by a batchnorm and ReLU nonlinearity with the exception of the final fully connected layer which has no nonlinearity and feeds into a softmax layer for classification.
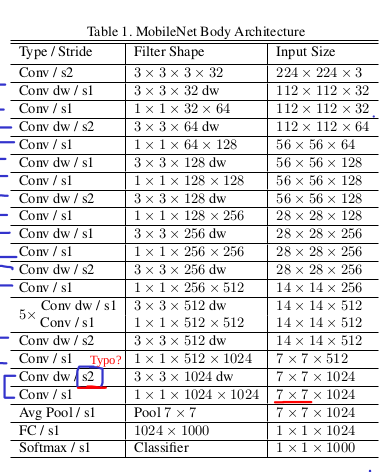
Important: As you can see above image got one ‘typo’ word. I was reading the paper. And i think, stride should be 1 (s1) not s2. So incase you are implementing paper on your own. Make sure you don’t miss this.
Code
Implementing depthwise separable convolution.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
import torch
import torch.nn as nn
class depthwise_pointwise(nn.Module):
def __init__(self, channels, stride=1):
super(depthwise_pointwise, self).__init__()
self.depthwise_layer= nn.Sequential(
nn.Conv2d(channels[0], channels[0],3,
groups=channels[0], padding=1, stride=stride),
nn.BatchNorm2d(channels[0]),
nn.ReLU(),
nn.Conv2d(channels[0],channels[1],1),
nn.BatchNorm2d(channels[1]),
nn.ReLU(),
)
def forward(self,x):
return self.depthwise_layer(x)
Main Mobilenet structure:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
class Mobilenet(nn.Module):
def __init__(self,depthwise_pointwise):
super(Mobilenet, self).__init__()
self.conv1= nn.Conv2d(3,32, 3, stride=2, padding=1)
self.bn1= nn.BatchNorm2d(32)
self.relu= nn.ReLU()
#depthwise sep
self.dw_s1= depthwise_pointwise([32,64], stride=1)
self.dw_s2= depthwise_pointwise([64,128], stride=2)
self.dw_s3= depthwise_pointwise([128,128])
self.dw_s4= depthwise_pointwise([128,256], stride=2)
self.dw_s5= depthwise_pointwise([256,256])
self.dw_s6= depthwise_pointwise([256,512], stride=2)
# x5 layer stack
self.dw_x5= depthwise_pointwise([512,512])
# dw layer
self.dw_s7= depthwise_pointwise([512,1024], stride=2)
self.dw_s8= depthwise_pointwise([1024,1024])
#avg pool
self.avgpool= nn.AdaptiveAvgPool2d((1,1))
self.fc= nn.Linear(1024,1000)
def forward(self,x):
x= self.relu(self.bn1(self.conv1(x)))
print(x.size())
x= self.dw_s1(x)
print(x.size())
x= self.dw_s2(x)
print(x.size())
x= self.dw_s3(x)
print(x.size())
x= self.dw_s4(x)
print(x.size())
x= self.dw_s5(x)
print(x.size())
x= self.dw_s6(x)
print(x.size())
for i in range(5):
x= self.dw_x5(x)
print(x.size())
x= self.dw_s7(x)
print(x.size())
x= self.dw_s8(x)
print(x.size())
x= self.avgpool(x)
print(x.size())
x=x.view(x.shape[0],-1)
x= self.fc(x)
print(x.size())
return x
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
mb= Mobilenet(depthwise_pointwise)
img= torch.randn(1,3,224,224)
k=mb(img)
> Output:
torch.Size([1, 32, 112, 112])
torch.Size([1, 64, 112, 112])
torch.Size([1, 128, 56, 56])
torch.Size([1, 128, 56, 56])
torch.Size([1, 256, 28, 28])
torch.Size([1, 256, 28, 28])
torch.Size([1, 512, 14, 14])
torch.Size([1, 512, 14, 14])
torch.Size([1, 1024, 7, 7])
torch.Size([1, 1024, 7, 7])
torch.Size([1, 1024, 1, 1])
torch.Size([1, 1000])
MobileNet Architecture :
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
Mobilenet(
(conv1): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(dw_s1): depthwise_pointwise(
(depthwise_layer): Sequential(
(0): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=32)
(1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(32, 64, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
)
)
(dw_s2): depthwise_pointwise(
(depthwise_layer): Sequential(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=64)
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
)
)
(dw_s3): depthwise_pointwise(
(depthwise_layer): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
)
)
(dw_s4): depthwise_pointwise(
(depthwise_layer): Sequential(
(0): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=128)
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
)
)
(dw_s5): depthwise_pointwise(
(depthwise_layer): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
)
)
(dw_s6): depthwise_pointwise(
(depthwise_layer): Sequential(
(0): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=256)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(256, 512, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
)
)
(dw_x5): depthwise_pointwise(
(depthwise_layer): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=512)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(512, 512, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
)
)
(dw_s7): depthwise_pointwise(
(depthwise_layer): Sequential(
(0): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), groups=512)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(512, 1024, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
)
)
(dw_s8): depthwise_pointwise(
(depthwise_layer): Sequential(
(0): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1024)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU()
(3): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1))
(4): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU()
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=1024, out_features=1000, bias=True)
)