What are we doing in this blog?
If you are here, then you know what are we doing. But still for the sake of clarity:
We are implementing popular Xception Network as represented by this paper. In this blog, i’ll be sharing my notes and learnings from this paper & Implemented code as well.
Intro:
After GoogLeNet proposal of inception module have led in Surge of various improved inception network. In case, you are instantly thinking about the movie ‘inception’. Yeah, that’s right. It’s taken from there. Convolutions within convolutions, this is inception module.
But what does inception module does differently?
It significantly reduces computational costs. Idea is not only about making accurate models but also making them deployable in outer world hardwares. Andrew Ng explains it the best in this video.
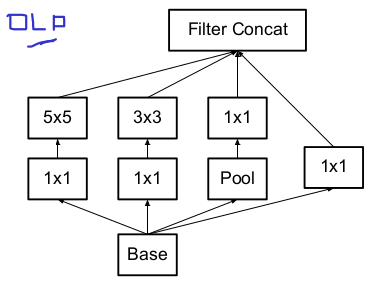
Below, Image represents standard GoogLeNet proposed inception module.
1x1 for dimensions reductions. And later on we are concatenating the output of the each branch of base.
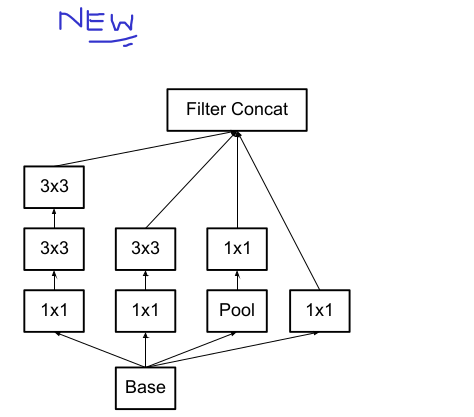
Paper - “Rethinking the Inception Architecture for Computer Vision” talks about getting rid of 5x5 convolutions and substituting it with two 3x3 convolution layers. This can result in dramatic decrease in computational costs from 120 millions to 1.2 million parameters & this is a giant leap of faith.
Author also suggests using asymmetric convolutions, e.g. n × 1. For example: using a 3 × 1 convolution followed by a 1 × 3 convolution
is equivalent to sliding a two layer network with the same receptive field as in a 3 × 3 convolution. But in practicality following issue was addressed in paper: "we have found that employing this factorization does not work well on early layers, but it gives very good results on medium grid-sizes (On m × m feature maps, where
m ranges between 12 and 20)."
After that author of Xception paper brought new improvement in the module which gives more better compactness and fairly easy implementation in code.
But what is this xception?
Slightly different Xception is! Ofcourse, its an extreme Inception module.
Xception complexity, yet simplicity:
Now after you have fair idea of what inception module looks like how it improved.
An “extreme” version of an Inception module, based on this stronger hypothesis, would first use a 1x1 convolution to map cross-channel correlations, and would then separately map the spatial correlations of every output channel.
This might be easily explained with the help of image:
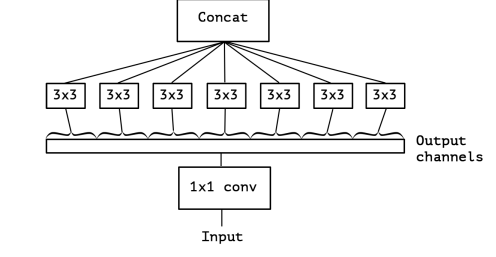
As you can see, Input (let’s say 64x150x150) goes through 1x1 convolutions and the output of this uses various 3x3 convolutions. This seperately goes through every output channels. This is almost same as depthwise seperable convolutions. Commonly called “separable convolution”. This is, a spatial convolution performed independently over each channel of an input, followed by a pointwise convolution, i.e. a 1x1 convolution, projecting the channels output by the depthwise convolution onto a new channel space.
Incase, this looks hard to under no worries we will understand it in code!
In tensorflow and keras it’s pretty easy to deal with separable conv. But in pytorch we have to change only one parameter in normal nn.Conv2d. As follows: nn.Conv2d(in_channel, out_channel,3, groups=in_channel, padding=1). ‘groups’ argument must be multiple of in_channel. This followed by pointwise convolution will complete our aim.
In pytorch official documentation, (At the time of writing this blog) they don’t say much about depthwise seperable conv.
DepthWise Separable Convolutions
Depthwise separable convolutions as usually implemented perform first channel-wise spatial convolution and then perform 1x1 convolution, whereas Inception performs the 1x1 convolution first. Below is a sample of how seperable Conv. is implemented –
Channel-wise spatial 3x3 convolution:
nn.Conv2d(channels[0], channels[0],3, groups=channels[0], padding=1)
Point-wise 1x1 convolution:
nn.Conv2d(channels[0], channels[1],1)
These will be used often in the Xception architecture. Before we proceed let’s look at complete architecture so we know what are we doing..

Dividing entire network into 3 sections:
- Entry Flow
- Middle Flow (repeated 8 times)
- Exit Flow
If you look closely, you will see skip connections also (i.e the Conv 1x1 layer which take previous input layer and adding in later layer). This is a bit similar with ResNet? Using residual layers and adding them up! This seen to significantly improve the accuracy of model without overfitting.
We are first implementing DepthWiseSeperable.
Note: Class DepthWiseSeperable include whole block between the skip connection as you can see in above image.
In class below we are taking channels list input. Which further will be used for parameters of seperable convolutions.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
class DepthWiseSeparable(nn.Module):
def __init__(self, channels, middle_flow= False):
super(DepthWiseSeparable, self).__init__()
# block for entry flow
if middle_flow== False:
self.block= nn.Sequential(
nn.ReLU(),
nn.Conv2d(channels[0], channels[0],3, groups=channels[0], padding=1),
nn.Conv2d(channels[0], channels[1],1),
nn.BatchNorm2d( channels[1]),
nn.ReLU(),
nn.Conv2d( channels[1], channels[1],3, groups=channels[1], padding=1),
nn.Conv2d( channels[1], channels[1],1),
nn.BatchNorm2d(channels[1]),
nn.MaxPool2d(3,stride=2, padding=1),
)
# block for middle flow
if middle_flow==True:
self.block= nn.Sequential(
nn.ReLU(),
nn.Conv2d(channels[0], channels[0],3, groups=channels[0], padding=1),
nn.Conv2d(channels[0], channels[1],1),
nn.BatchNorm2d( channels[1]),
nn.ReLU(),
nn.Conv2d( channels[1], channels[1],3, groups=channels[1], padding=1),
nn.Conv2d( channels[1], channels[1],1),
nn.BatchNorm2d(channels[1]),
nn.ReLU(),
nn.Conv2d( channels[1], channels[1],3, groups=channels[1], padding=1),
nn.Conv2d( channels[1], channels[1],1),
)
# block for exit flow
if middle_flow=='Exit':
self.block= nn.Sequential(
nn.Conv2d(channels[0], channels[0],3, groups=channels[0], padding=1),
nn.Conv2d(channels[0], channels[1],1),
nn.BatchNorm2d( channels[1]),
nn.ReLU(),
nn.Conv2d( channels[1], channels[1],3, groups=channels[1], padding=1),
nn.Conv2d( channels[1], channels[2],1),
nn.BatchNorm2d(channels[2]),
nn.ReLU(),
)
def forward(self,x):
x= self.block(x)
return x
Below is Main xception class which will use above class to create whole network.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
class Xception(nn.Module):
def __init__(self, DepthWiseSeparable):
super(Xception, self).__init__()
self.conv1_3x3 = nn.Conv2d(3,32,3,stride=2,padding=1)
self.bn1 =nn.BatchNorm2d(32)
self.relu = nn.ReLU()
self.conv2_3x3= nn.Conv2d(32,64,3,stride=1,padding=1)
self.bn2 =nn.BatchNorm2d(64)
self.relu= nn.ReLU()
#Entry flow
self.block_3x3= DepthWiseSeparable(channels=[64,128])
self.downsample_1= nn.Conv2d(64,128,1,stride=2)
self.block_3x3_256= DepthWiseSeparable(channels=[128,256])
self.downsample_2= nn.Conv2d(128,256,1,stride=2)
self.block_3x3_728= DepthWiseSeparable(channels=[256,728])
self.downsample_3= nn.Conv2d(256,728,1,stride=2)
#Middle Flow
self.block_3x3_middle= DepthWiseSeparable(channels=[728,728], middle_flow=True)
#Exit flow
self.block_3x3_exit = DepthWiseSeparable(channels=[728,1024])
self.downsample_4= nn.Conv2d(728,1024,1,stride=2)
self.block_3x3_exit_2 = DepthWiseSeparable(channels=[1024,1536,2048], middle_flow='Exit')
self.avgpool= nn.AdaptiveAvgPool2d((1,1))
self.fc= nn.Linear(2048,1000)
def forward(self,x):
x= self.relu(self.bn1(self.conv1_3x3(x)))
print(x.size())
x_identity = self.relu(self.bn2(self.conv2_3x3(x)))
print(x_identity.size())
x_res_1= self.block_3x3(x_identity)
print(x_res_1.size())
x_identity= self.downsample_1(x_identity)
print(x_identity.size())
x_identity= x_identity+x_res_1
x_res_2= self.block_3x3_256(x_identity)
print(x_res_2.size())
x_identity= self.downsample_2(x_identity)
print(x_identity.size())
x_identity= x_identity+x_res_2
x_res_3= self.block_3x3_728(x_identity)
print(x_res_3.size())
x_identity= self.downsample_3(x_identity)
print(x_identity.size())
x_identity= x_identity+x_res_3
for i in range(9):
x_res_4= self.block_3x3_middle(x_identity)
x_identity= x_identity+x_res_4
print(x_identity.size())
x_res_5= self.block_3x3_exit(x_identity)
x_identity= self.downsample_4(x_identity)
x_identity= x_identity+x_res_5
print(x_identity.size())
x_res_6= self.block_3x3_exit_2(x_identity)
print(x_res_6.size())
x= self.avgpool(x_res_6)
print(x.size())
x= x.view(x.shape[0],-1)
print(x.size())
x= self.fc(x)
print(x.size())
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
img= torch.randn(1,3,299,299)
net= Xception(DepthWiseSeparable)
net(img)
> Output:
torch.Size([1, 32, 150, 150])
torch.Size([1, 64, 150, 150])
torch.Size([1, 128, 75, 75])
torch.Size([1, 128, 75, 75])
torch.Size([1, 256, 38, 38])
torch.Size([1, 256, 38, 38])
torch.Size([1, 728, 19, 19])
torch.Size([1, 728, 19, 19])
torch.Size([1, 728, 19, 19])
torch.Size([1, 1024, 10, 10])
torch.Size([1, 2048, 10, 10])
torch.Size([1, 2048, 1, 1])
torch.Size([1, 2048])
torch.Size([1, 1000])
Model :
Our model will look like something like
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
Xception(
(conv1_3x3): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1))
(bn1): BatchNorm2d(32, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU()
(conv2_3x3): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(block_3x3): DepthWiseSeparable(
(block): Sequential(
(0): ReLU()
(1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=64)
(2): Conv2d(64, 128, kernel_size=(1, 1), stride=(1, 1))
(3): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128)
(6): Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
)
(downsample_1): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2))
(block_3x3_256): DepthWiseSeparable(
(block): Sequential(
(0): ReLU()
(1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=128)
(2): Conv2d(128, 256, kernel_size=(1, 1), stride=(1, 1))
(3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
(6): Conv2d(256, 256, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
)
(downsample_2): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2))
(block_3x3_728): DepthWiseSeparable(
(block): Sequential(
(0): ReLU()
(1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=256)
(2): Conv2d(256, 728, kernel_size=(1, 1), stride=(1, 1))
(3): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728)
(6): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
)
(downsample_3): Conv2d(256, 728, kernel_size=(1, 1), stride=(2, 2))
(block_3x3_middle): DepthWiseSeparable(
(block): Sequential(
(0): ReLU()
(1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728)
(2): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1))
(3): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728)
(6): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(728, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): ReLU()
(9): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728)
(10): Conv2d(728, 728, kernel_size=(1, 1), stride=(1, 1))
)
)
(block_3x3_exit): DepthWiseSeparable(
(block): Sequential(
(0): ReLU()
(1): Conv2d(728, 728, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=728)
(2): Conv2d(728, 1024, kernel_size=(1, 1), stride=(1, 1))
(3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(4): ReLU()
(5): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1024)
(6): Conv2d(1024, 1024, kernel_size=(1, 1), stride=(1, 1))
(7): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(8): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
)
)
(downsample_4): Conv2d(728, 1024, kernel_size=(1, 1), stride=(2, 2))
(block_3x3_exit_2): DepthWiseSeparable(
(block): Sequential(
(0): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1024)
(1): Conv2d(1024, 1536, kernel_size=(1, 1), stride=(1, 1))
(2): BatchNorm2d(1536, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(3): ReLU()
(4): Conv2d(1536, 1536, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), groups=1536)
(5): Conv2d(1536, 2048, kernel_size=(1, 1), stride=(1, 1))
(6): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(7): ReLU()
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)