What are we doing? And Why?
If you are a datascientist or computer vision researcher who always looking for neat image or any sort of dataset because it’s sometimes so hard to find right dataset for you. In this post, i am sharing some resources which would be super helpful for you. I will also show the right way to download them in case of Google Open Image Dataset. What right way you may ask? It’s simply a python script which will do the job for you. You don’t need to rush in anyway.
Open Images Dataset V6
When i was starting out from scratch. It was quite difficult to know from where to download the dataset. Or if that dataset right for you. Open Images Dataset V6 by Google is an amazing source to download the data.
You can find it here. There will be plethora of categories in the dropdown menu. It would look something like this.
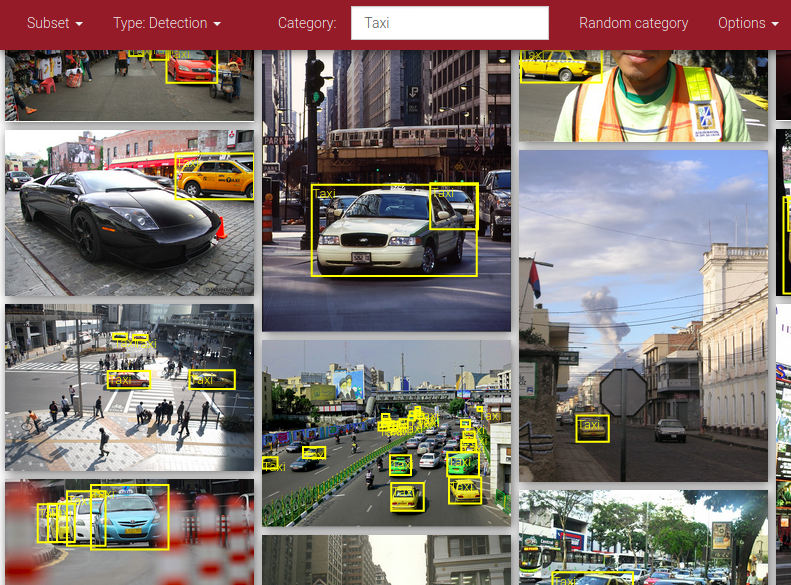
Brief
As you can see, the category for this tutorial i have chosen is taxi. You may chose anything else, Ofcourse!. There are several filters on the top of red bar in the website which is important to know about. Like:
- Subset : (Train, Validation)
- Type: (Detection, Segementation)
Subset is only to show you the content which will be downloaded if you download train or validation filtered data.
Type is crucial, it will give you whatever type of problem deal with. For example, for this example we have used detection. So the images we are getting is bounding boxes. If you switch it to, segmentation you get segemented image. As simple as that.
How to download?
It’s quite difficult to ambigous to download from the website. But fortunately we have tool which makes it easy to one liner!
We use a tool name OIDv4_ToolKit available on github. It makes is fairly easy to download images.
Cloning the github repo.
📝 Note: If you are running the command in a terminal. Omit “!” .
1
2
3
4
5
6
> git clone https://github.com/theAIGuysCode/OIDv4_ToolKit.git
Cloning into 'OIDv4_ToolKit'...
remote: Enumerating objects: 444, done.
remote: Total 444 (delta 0), reused 0 (delta 0), pack-reused 444
Receiving objects: 100% (444/444), 34.09 MiB | 35.95 MiB/s, done.
Resolving deltas: 100% (157/157), done.
Moving inside directory and extracting some files. You don’t need to bother much about this, just copy paste and run on your machine.
1
2
3
4
> cd OIDv4_ToolKit/
> curl "https://d1vvhvl2y92vvt.cloudfront.net/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"
> unzip awscliv2.zip
> sudo ./aws/install
Now, here comes the magic. One command where you specify :
class: In our case, we will downloadTaxiimages. You can download multiple classes by just typing class one after another.type_csv: Do you want to download train data? Validation data?limit: How many images we want to download? I am downloading 100 as an example.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
> python main.py downloader --classes Taxi --type_csv train --limit 100
.' `.|_ _||_ _ `. | | | |
/ .-. \ | | | | `. \ _ __ | |__| |_
| | | | | | | | | |[ \ [ ]|____ _|
\ `-' /_| |_ _| |_.' / \ \/ / _| |_
`.___.'|_____||______.' \__/ |_____|
_____ _ _
(____ \ | | | |
_ \ \ ___ _ _ _ ____ | | ___ ____ _ | | ____ ____
| | | / _ \| | | | _ \| |/ _ \ / _ |/ || |/ _ )/ ___)
| |__/ / |_| | | | | | | | | |_| ( ( | ( (_| ( (/ /| |
|_____/ \___/ \____|_| |_|_|\___/ \_||_|\____|\____)_|
[INFO] | Downloading Taxi.
[ERROR] | Missing the class-descriptions-boxable.csv file.
[DOWNLOAD] | Do you want to download the missing file? [Y/n] Y
...145%, 0 MB, 31097 KB/s, 0 seconds passed
[DOWNLOAD] | File class-descriptions-boxable.csv downloaded into OID/csv_folder/class-descriptions-boxable.csv.
[ERROR] | Missing the train-annotations-bbox.csv file.
[DOWNLOAD] | Do you want to download the missing file? [Y/n] Y
...100%, 1138 MB, 33727 KB/s, 34 seconds passed
[DOWNLOAD] | File train-annotations-bbox.csv downloaded into OID/csv_folder/train-annotations-bbox.csv.
Taxi
[INFO] | Downloading train images.
[INFO] | [INFO] Found 1434 online images for train.
[INFO] | Limiting to 100 images.
[INFO] | Download of 100 images in train.
100% 100/100 [02:08<00:00, 1.28s/it]
[INFO] | Done!
[INFO] | Creating labels for Taxi of train.
[INFO] | Labels creation completed.
Sample image from data
Now it has been downloaded. Dataset will be downloaded in the file /OID/Dataset/train/
Let’s see the sample image?
1
2
> from PIL import Image
> Image.open('/content/OIDv4_ToolKit/OID/Dataset/train/Taxi/23274c285653cc1c.jpg')

So it looks pretty good! Remember i have only downloaded 100 images. You can download with any limit. If its available on dataset. It will be downloaded. We also have bounding boxes in labels folder.
⚡ Tip: csv file have been downloaded in
csv_folder. You can use it as pandas dataframe for more flexible usage of data.
Open Public datasets
As a data scientist, you dont always deal with image dataset. So, this Github Repo got very detailed list of every dataset for gamut of professions.
⚡ Tip: If you are new to github. You can fork it and contribute to it as well.
Amazon, Google, Microsoft Public Dataset
Waait.. we just discussed google dataset a while ago. That was especially for image based problems. Incase you want to research for the data yourself that you struggling to find. The Google Dataset Search engine will help you to research more about it.
Like Google, Amazon also have some public dataset to help you with your research.
And so do, Microsoft .
Datasets we have discussed so far. They will definitely provide the edge you looking for (if you look correctly). They are almost all you need. Although there are sites like kaggle, datatruks but as we have mentioned google dataset engine. It automatically directs you to the sites.